

장시간 서비스하는 Production 환경의 프로그램에서 특히 유의해야 하는 녀석들이 있죠
이번에 얘기할 녀석은 힘순찐 메모리 누수(Memory Leak)입니다
처음엔 안 보이다가 한창 돌아가면 나타나는 녀석이죠
처음부터 잘 개발했으면 문제가 없겠지만 개발이란 게 그렇지 만만하진 않습니다
장시간 성능 시험을 돌리면서 발생한 Memory Leak을 발견하고 해결한 과정을
가볍게 공유합니다:)
상황
회사에서 SKB 관련 상용 서비스 GW 개발을 하고 있습니다
전부 C로 설계된 상황에 AS 프로세스와 gRPC로 연동하는
gRPC Interface 블럭만 Go로 설계되어 제가 담당하게 되었습니다
선행과제 개발을 하면서 k8s나 Go에 대한 호감이 MAX에 이를 쯤이라
재밌는 기회라 생각했지만
Production 환경에 적용하기로는 걱정스러운 부분도 있었죠
안타깝게도 이번 과제에서 저희 팀에서 저 말고 go를 잘 아시는 분이 없었기에
제대로 된 코드 리뷰도 이뤄지지 못한 상황이었습니다
(나조차 나를 못믿는 상황...ㅎㅎ)
스스로 다시 확인하고 다시 확인하고 꼼꼼하게 보는 수밖에 없었죠
대략 1만 5천 줄 정도 되는 코드에 10개의 기능 모듈로 이루어진
gRPC 인터페이스 블록을 만들었습니다
작진 않죠
특히나 안정성이나 성능에 만전을 기하며 개발했습니다
QA팀에서 테스트가 들어갔으며
기본적으로 Unit, Acceptance 테스트 기반으로 자체 검증을 끝냈기 때문에
기능적으론 문제가 없었으며 이제 요구사항을 만족하기 위한
최대 성능, 장시간 성능 시험에 돌입합니다
기준 아래와 같습니다
- 3일 내내 초당 500 호 처리 : 500 CPS (Call Per Seconds)
그리 높은 수치는 아니었습니다
퇴근 전까지 모니터링하며 내 문제는 없구나 안심하고 퇴근!
다음날 출근하여 아침에 이상한 통계를 발견합니다ㅎㅎ
문제 1
안정적으로 돌던 녀석이 timeout 통계가 찍혀있습니다
제 쪽과 연결하는 AS 프로세스에서 연결이 끊겼다고 합니다
놀랍게도 Call log / Process log는 정상입니다(!)
OAM의 리소스 통계를 확인해보니 소름이 돋습니다
갑자기 메모리를 언제 그렇게 먹었어..?
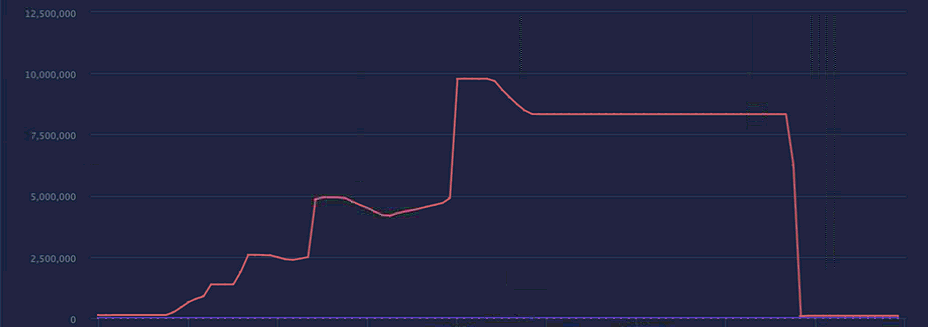
Log는 정상이며 메모리는 쭉쭉 늘어나 있는 상황은 Full GC가 발생한 것으로 생각이 듭니다
(물론, Go에서는 세대별 GC를 수행하지 않기 때문에 Full GC라는 것은 없습니다)
(JAVA의 GC가 익숙한 개념이라 당시 Full GC가 발생한 것 같다고 분석했을뿐...)
Go Memory 관련한 자세한 사항은 아래 포스팅에 전부 정리되어 있습니다
Golang Memory Management
이번엔 Go의 메모리 관리에 대해 정리해보려합니다 Go가 1.17이 릴리즈되는 현재 시점에서 한글화된 문서중에 잘 정리된 문서가 없더라구요.. (있어도 너무 초창기 버전 Go의 내용) 이제 Go도 연식
syntaxsugar.tistory.com
위의 포스팅이 이 문제를 해결하면서 분석 정리한 Go Memory Management 이지요..
golang은 할당된 Heap Memory가 모자라면 OS에 요청해 조금씩 추가로 할당받고
GC가 수행된 직후의 Memory크기의 2배가 될 때마다 GC를 다시 수행합니다
그래서 위와 같이 Memory가 계속해서 증가하는 경우
조금씩 오르다가 기존의 2배씩 Memory가 증가할 때마다 GC가 발생해
조금씩 줄어든 것을 확인할 수 있었고 해당 부분에 STW(Stop The World)가 발생한 것이었습니다
이로 인해 해당 프로세스와 연동하는 AS에서는 timeout이 발생했으며
내부적으로는 아무런 문제도 발생하지 않은 것처럼 진행된 현상이었습니다
당시 그렇게 큰 데이터를 저장할 필요가 없는 시험이었기 때문에
GC 튜닝이 필요한 문제가 아니라 memleak이란걸 바로 깨달을 수 있었습니다
초기에 보이지 않아 memleak에 크게 신경을 안 썼는데 큰 실수를 할뻔했죠
당시에는 Go의 Internal Memory 구조에 대해 잘 몰라서
관련된 조사를 하기 시작했고 뭘 놓쳤을까 고민도 많이 했었습니다
아래의 Memroy Leak에 대한 좋은 글들도 있었으나
https://hackernoon.com/avoiding-memory-leak-in-golang-api-1843ef45fca8
Avoiding Memory Leak in Golang API | Hacker Noon
You must read this before releasing your Golang API into production. Based on our true story at Kurio, how we struggling for every release because we are not doing it in the right ways.
hackernoon.com
- 대부분 Actor 모델로 구성
- 죽지 않는 go routine은 없음
- Async 구조에서 제대로 Timeout 처리
위의 설계를 가진 제 프로세스에서 발생할만한 문제는 없었습니다
go에는 프로세스 상태를 확인할 수 있는 pprof이라는 tool이 있습니다
go tool pprof을 활성화하여 다시 성능시험을 요청하고
프로세스 상태를 모니터링해봅니다
[pprof 사용]
/*
/net/http/pprof을 사용합니다
https://golang.org/pkg/net/http/pprof/
pprof - The Go Programming Language
Package pprof import "net/http/pprof" Overview Index Overview ▹ Overview ▾ Package pprof serves via its HTTP server runtime profiling data in the format expected by the pprof visualization tool. The package is typically only imported for the side effec
golang.org
pprof을 import 하고
아래 주소를 핸들링하는 서버를 열면 됩니다

이후 브라우저로 해당 서버의 port로 접근하면 시각화된 pprof 데이터를 확인할 수 있습니다
전 아래 cmd로 1분마다 메모리 상태를 가져오게 했습니다
go tool pprof -top http://192.168.5.175:7070/debug/pprof/heap | head -n 30
어느 부분에서 메모리를 얼마나 차지하는지 알려줍니다
list를 통해 어느 부분에서 발생하는지도 확인 가능
*/
pdf로 export 해보면 꽤나 잘 나오는 것 같아 보이지만
어디서 시작된 메모리인지는 알 수 없는 경우가 대부분이라 list로 직접 확인해봐야 합니다
list는 코드 라인 단위로 메모리를 확인할 수 있어 매우 유용합니다
golang은 밑바닥 끝부터 코드 확인이 가능해서 이런 점이 참 좋습니다
해결 1
발견된 문제는 sessionID 관리하는 과정에서 발생하는 문제였습니다
새로운 호(call)가 발생할 때마다 새로운 sessionID를 발생시키는데
해당 sessionID에 대한 라우팅 정보 등이 map에 계속 쌓이고 있어 문제가 일어나는 거였습니다
세션 이중화 등의 기능 때문에 해당 세션이 되살아날 가능성이 있어
메모리에 세션 정보를 계속 붙들고 있으니 장시간 성능시험 시에만 문제가 되었던 거죠
결국 연동규격을 협의하여
살아날 수 있는 세션, 되살아날 수 없는 세션, 끝난 세션을
구분하여 map에서 제거하도록 처리하여 해결되었습니다
문제 2
근데 다시 돌려보니 미세하긴 한데 아아아아주 미세하게 메모리가 꾸준히 증가하는 게 또 보입니다ㅋㅋㅋㅋ
pprof으로 시각화된 데이터를 pdf로 export 할 수 있습니다
큰 메모리 leak에 가려 안보였던 부분이 아래처럼 보이기 시작합니다

이번 문제는 다른 분들도 겪을 수 있는 문제 기도하고
워낙 분석하기 좋게 이쁘게 잘 나와서 첨부합니다
Bold체 부분이 지워지지 않고 남아있는 큰 메모리 정보입니다
gRPC Client 쪽 연동 모듈의 startHealthCheck 부분에서부터
메모리가 발생해 지워지지 않는 것을 한눈에 발견할 수 있습니다
/*
첫 번째 문제에서 말했듯이
보통 위와 같이 일반적인 시각화로 확인할 수 없는 경우가 많습니다
아래처럼 알려주거든요
'해당 부분에서 메모리가 안 지워졌어!'
'어디서 생긴 건진 난 모름ㅎ'
딱 봤을 땐
'읭 왠 context 부분에서 메모리가 남아있지..?'
'내부 go package에 문제가 있는 거야?..?'
라고 착각할 수 있습니다
*/
해결 2
문제 코드를 살펴봅니다
아래는 설정한 시간마다 gRPC client가
server에 healthcheck를 보내는 go routine입니다
(실제론 여러 function들로 나뉜 코드지만 한눈에 문제를 볼 수 있도록 하기 위해)
(아래와 같이 지저분한 코드 덩어리로 첨부되었음을 양해드립니다)
go func() {
for {
select {
case <-ticker.C:
ctx, cancel := context.WithTimeout(context.Background(), healthcheckTimeout)
_, err := gc.healthClient.Check(ctx, &healthpb.HealthCheckRequest{})
defer cancel()
if err != nil {
if gc.context.Err() != nil {
return
}
if gc.isHealthy {
gc.currentBadCount++
logger.Warn("[grpcclient]Failed to check health of as(%s) - %d/%d : %s",
gc.asID, gc.currentBadCount, healthcheckStatusBadCount, err)
if gc.currentBadCount >= healthcheckStatusBadCount {
logger.Warn("[grpcclient]Health status was turned unhealthy of as(%s)", gc.asID)
gc.isHealthy = false
}
}
} else {
if gc.currentBadCount > 0 {
logger.Info("[grpcclient]Success to check health of as(%s)", gc.asID)
gc.currentBadCount = 0
}
if !gc.isHealthy {
logger.Info("[grpcclient]Health status was recovered of as(%s)", gc.asID)
gc.isHealthy = true
}
}
case <-gc.stopHealth:
ticker.Stop()
return
}
}
}()
아무 생각 없이 ticker select에서는 무한루프 for를 사용해왔고
아무 생각 없이 context를 매번 사용할 때마다 defer를 같이 사용했습니다
큰 문제가 아닐 수 있는 부분이지만
이 두 개의 무지성이 합쳐지면 문제가 발생합니다
gc.stopHealth 채널을 받기 전까지는 죽지 않는 goroutine인데
for 때문에 끝나질 않으니 7번째 줄의 defer가 실행이 안 되는 문제였습니다
어처구니가 없는 실수죠
defer가 없어도 되는 부분이기 때문에 제거하여 해결하였습니다
항상 알고 나면 참 시시하죠
(결과는 시시하지 않으면서...)
관용적인 코드도 무지성으로 쓰지 말고 의심하고
생각해야 한다는 점을 다시금 깨닫습니다...
방지 대책
해결은 해결한 것이고...
더 성장하기 위해선 이러한 사고를 방지 하기 위한 대책을 하나 마련하자 생각했습니다
valgrind 처럼 leak을 detect해주는 Uber의 패키지가 있긴했습니다
GitHub - uber-go/goleak: Goroutine leak detector
Goroutine leak detector. Contribute to uber-go/goleak development by creating an account on GitHub.
github.com
해당 패키지를 이용해서 테스트 케이스를 작성하면 leak을 사전에 파악할 수 있겠네요
goleak에 대해서도 차후에 포스팅해보도록 하겠습니다
그간 선행과제에서는 늘 최대 성능만 테스트하니
이런 중요한 부분을 간과해왔네요
다행히 큰 사고 없이 시험 중에 문제를 파악할 수 있었고
장시간 성능 시험을 진행하면서
크게 얻어갈 게 있어 즐거웠습니다
Production 개발은 역시 좋은 경험이었던 것 같습니다
'Programming > Go' 카테고리의 다른 글
| Go/Golang Test (2) | 2021.08.26 |
|---|---|
| Go/Golang Memory Management (16) | 2021.08.22 |
| Go/Golang Protobuf Compile Guide (0) | 2021.08.16 |
| Go/Golang Configuration (0) | 2021.08.16 |
| Go/Golang awesome-go (0) | 2021.08.11 |
장시간 서비스하는 Production 환경의 프로그램에서 특히 유의해야 하는 녀석들이 있죠
이번에 얘기할 녀석은 힘순찐 메모리 누수(Memory Leak)입니다
처음엔 안 보이다가 한창 돌아가면 나타나는 녀석이죠
처음부터 잘 개발했으면 문제가 없겠지만 개발이란 게 그렇지 만만하진 않습니다
장시간 성능 시험을 돌리면서 발생한 Memory Leak을 발견하고 해결한 과정을
가볍게 공유합니다:)
상황
회사에서 SKB 관련 상용 서비스 GW 개발을 하고 있습니다
전부 C로 설계된 상황에 AS 프로세스와 gRPC로 연동하는
gRPC Interface 블럭만 Go로 설계되어 제가 담당하게 되었습니다
선행과제 개발을 하면서 k8s나 Go에 대한 호감이 MAX에 이를 쯤이라
재밌는 기회라 생각했지만
Production 환경에 적용하기로는 걱정스러운 부분도 있었죠
안타깝게도 이번 과제에서 저희 팀에서 저 말고 go를 잘 아시는 분이 없었기에
제대로 된 코드 리뷰도 이뤄지지 못한 상황이었습니다
(나조차 나를 못믿는 상황...ㅎㅎ)
스스로 다시 확인하고 다시 확인하고 꼼꼼하게 보는 수밖에 없었죠
대략 1만 5천 줄 정도 되는 코드에 10개의 기능 모듈로 이루어진
gRPC 인터페이스 블록을 만들었습니다
작진 않죠
특히나 안정성이나 성능에 만전을 기하며 개발했습니다
QA팀에서 테스트가 들어갔으며
기본적으로 Unit, Acceptance 테스트 기반으로 자체 검증을 끝냈기 때문에
기능적으론 문제가 없었으며 이제 요구사항을 만족하기 위한
최대 성능, 장시간 성능 시험에 돌입합니다
기준 아래와 같습니다
- 3일 내내 초당 500 호 처리 : 500 CPS (Call Per Seconds)
그리 높은 수치는 아니었습니다
퇴근 전까지 모니터링하며 내 문제는 없구나 안심하고 퇴근!
다음날 출근하여 아침에 이상한 통계를 발견합니다ㅎㅎ
문제 1
안정적으로 돌던 녀석이 timeout 통계가 찍혀있습니다
제 쪽과 연결하는 AS 프로세스에서 연결이 끊겼다고 합니다
놀랍게도 Call log / Process log는 정상입니다(!)
OAM의 리소스 통계를 확인해보니 소름이 돋습니다
갑자기 메모리를 언제 그렇게 먹었어..?
Log는 정상이며 메모리는 쭉쭉 늘어나 있는 상황은 Full GC가 발생한 것으로 생각이 듭니다
(물론, Go에서는 세대별 GC를 수행하지 않기 때문에 Full GC라는 것은 없습니다)
(JAVA의 GC가 익숙한 개념이라 당시 Full GC가 발생한 것 같다고 분석했을뿐...)
Go Memory 관련한 자세한 사항은 아래 포스팅에 전부 정리되어 있습니다
Golang Memory Management
이번엔 Go의 메모리 관리에 대해 정리해보려합니다 Go가 1.17이 릴리즈되는 현재 시점에서 한글화된 문서중에 잘 정리된 문서가 없더라구요.. (있어도 너무 초창기 버전 Go의 내용) 이제 Go도 연식
syntaxsugar.tistory.com
위의 포스팅이 이 문제를 해결하면서 분석 정리한 Go Memory Management 이지요..
golang은 할당된 Heap Memory가 모자라면 OS에 요청해 조금씩 추가로 할당받고
GC가 수행된 직후의 Memory크기의 2배가 될 때마다 GC를 다시 수행합니다
그래서 위와 같이 Memory가 계속해서 증가하는 경우
조금씩 오르다가 기존의 2배씩 Memory가 증가할 때마다 GC가 발생해
조금씩 줄어든 것을 확인할 수 있었고 해당 부분에 STW(Stop The World)가 발생한 것이었습니다
이로 인해 해당 프로세스와 연동하는 AS에서는 timeout이 발생했으며
내부적으로는 아무런 문제도 발생하지 않은 것처럼 진행된 현상이었습니다
당시 그렇게 큰 데이터를 저장할 필요가 없는 시험이었기 때문에
GC 튜닝이 필요한 문제가 아니라 memleak이란걸 바로 깨달을 수 있었습니다
초기에 보이지 않아 memleak에 크게 신경을 안 썼는데 큰 실수를 할뻔했죠
당시에는 Go의 Internal Memory 구조에 대해 잘 몰라서
관련된 조사를 하기 시작했고 뭘 놓쳤을까 고민도 많이 했었습니다
아래의 Memroy Leak에 대한 좋은 글들도 있었으나
https://hackernoon.com/avoiding-memory-leak-in-golang-api-1843ef45fca8
Avoiding Memory Leak in Golang API | Hacker Noon
You must read this before releasing your Golang API into production. Based on our true story at Kurio, how we struggling for every release because we are not doing it in the right ways.
hackernoon.com
- 대부분 Actor 모델로 구성
- 죽지 않는 go routine은 없음
- Async 구조에서 제대로 Timeout 처리
위의 설계를 가진 제 프로세스에서 발생할만한 문제는 없었습니다
go에는 프로세스 상태를 확인할 수 있는 pprof이라는 tool이 있습니다
go tool pprof을 활성화하여 다시 성능시험을 요청하고
프로세스 상태를 모니터링해봅니다
[pprof 사용]
/*
/net/http/pprof을 사용합니다
https://golang.org/pkg/net/http/pprof/
pprof - The Go Programming Language
Package pprof import "net/http/pprof" Overview Index Overview ▹ Overview ▾ Package pprof serves via its HTTP server runtime profiling data in the format expected by the pprof visualization tool. The package is typically only imported for the side effec
golang.org
pprof을 import 하고
아래 주소를 핸들링하는 서버를 열면 됩니다
이후 브라우저로 해당 서버의 port로 접근하면 시각화된 pprof 데이터를 확인할 수 있습니다
전 아래 cmd로 1분마다 메모리 상태를 가져오게 했습니다
go tool pprof -top http://192.168.5.175:7070/debug/pprof/heap | head -n 30
어느 부분에서 메모리를 얼마나 차지하는지 알려줍니다
list를 통해 어느 부분에서 발생하는지도 확인 가능
*/
pdf로 export 해보면 꽤나 잘 나오는 것 같아 보이지만
어디서 시작된 메모리인지는 알 수 없는 경우가 대부분이라 list로 직접 확인해봐야 합니다
list는 코드 라인 단위로 메모리를 확인할 수 있어 매우 유용합니다
golang은 밑바닥 끝부터 코드 확인이 가능해서 이런 점이 참 좋습니다
해결 1
발견된 문제는 sessionID 관리하는 과정에서 발생하는 문제였습니다
새로운 호(call)가 발생할 때마다 새로운 sessionID를 발생시키는데
해당 sessionID에 대한 라우팅 정보 등이 map에 계속 쌓이고 있어 문제가 일어나는 거였습니다
세션 이중화 등의 기능 때문에 해당 세션이 되살아날 가능성이 있어
메모리에 세션 정보를 계속 붙들고 있으니 장시간 성능시험 시에만 문제가 되었던 거죠
결국 연동규격을 협의하여
살아날 수 있는 세션, 되살아날 수 없는 세션, 끝난 세션을
구분하여 map에서 제거하도록 처리하여 해결되었습니다
문제 2
근데 다시 돌려보니 미세하긴 한데 아아아아주 미세하게 메모리가 꾸준히 증가하는 게 또 보입니다ㅋㅋㅋㅋ
pprof으로 시각화된 데이터를 pdf로 export 할 수 있습니다
큰 메모리 leak에 가려 안보였던 부분이 아래처럼 보이기 시작합니다
이번 문제는 다른 분들도 겪을 수 있는 문제 기도하고
워낙 분석하기 좋게 이쁘게 잘 나와서 첨부합니다
Bold체 부분이 지워지지 않고 남아있는 큰 메모리 정보입니다
gRPC Client 쪽 연동 모듈의 startHealthCheck 부분에서부터
메모리가 발생해 지워지지 않는 것을 한눈에 발견할 수 있습니다
/*
첫 번째 문제에서 말했듯이
보통 위와 같이 일반적인 시각화로 확인할 수 없는 경우가 많습니다
아래처럼 알려주거든요
'해당 부분에서 메모리가 안 지워졌어!'
'어디서 생긴 건진 난 모름ㅎ'
딱 봤을 땐
'읭 왠 context 부분에서 메모리가 남아있지..?'
'내부 go package에 문제가 있는 거야?..?'
라고 착각할 수 있습니다
*/
해결 2
문제 코드를 살펴봅니다
아래는 설정한 시간마다 gRPC client가
server에 healthcheck를 보내는 go routine입니다
(실제론 여러 function들로 나뉜 코드지만 한눈에 문제를 볼 수 있도록 하기 위해)
(아래와 같이 지저분한 코드 덩어리로 첨부되었음을 양해드립니다)
go func() {
for {
select {
case <-ticker.C:
ctx, cancel := context.WithTimeout(context.Background(), healthcheckTimeout)
_, err := gc.healthClient.Check(ctx, &healthpb.HealthCheckRequest{})
defer cancel()
if err != nil {
if gc.context.Err() != nil {
return
}
if gc.isHealthy {
gc.currentBadCount++
logger.Warn("[grpcclient]Failed to check health of as(%s) - %d/%d : %s",
gc.asID, gc.currentBadCount, healthcheckStatusBadCount, err)
if gc.currentBadCount >= healthcheckStatusBadCount {
logger.Warn("[grpcclient]Health status was turned unhealthy of as(%s)", gc.asID)
gc.isHealthy = false
}
}
} else {
if gc.currentBadCount > 0 {
logger.Info("[grpcclient]Success to check health of as(%s)", gc.asID)
gc.currentBadCount = 0
}
if !gc.isHealthy {
logger.Info("[grpcclient]Health status was recovered of as(%s)", gc.asID)
gc.isHealthy = true
}
}
case <-gc.stopHealth:
ticker.Stop()
return
}
}
}()
아무 생각 없이 ticker select에서는 무한루프 for를 사용해왔고
아무 생각 없이 context를 매번 사용할 때마다 defer를 같이 사용했습니다
큰 문제가 아닐 수 있는 부분이지만
이 두 개의 무지성이 합쳐지면 문제가 발생합니다
gc.stopHealth 채널을 받기 전까지는 죽지 않는 goroutine인데
for 때문에 끝나질 않으니 7번째 줄의 defer가 실행이 안 되는 문제였습니다
어처구니가 없는 실수죠
defer가 없어도 되는 부분이기 때문에 제거하여 해결하였습니다
항상 알고 나면 참 시시하죠
(결과는 시시하지 않으면서...)
관용적인 코드도 무지성으로 쓰지 말고 의심하고
생각해야 한다는 점을 다시금 깨닫습니다...
방지 대책
해결은 해결한 것이고...
더 성장하기 위해선 이러한 사고를 방지 하기 위한 대책을 하나 마련하자 생각했습니다
valgrind 처럼 leak을 detect해주는 Uber의 패키지가 있긴했습니다
GitHub - uber-go/goleak: Goroutine leak detector
Goroutine leak detector. Contribute to uber-go/goleak development by creating an account on GitHub.
github.com
해당 패키지를 이용해서 테스트 케이스를 작성하면 leak을 사전에 파악할 수 있겠네요
goleak에 대해서도 차후에 포스팅해보도록 하겠습니다
그간 선행과제에서는 늘 최대 성능만 테스트하니
이런 중요한 부분을 간과해왔네요
다행히 큰 사고 없이 시험 중에 문제를 파악할 수 있었고
장시간 성능 시험을 진행하면서
크게 얻어갈 게 있어 즐거웠습니다
Production 개발은 역시 좋은 경험이었던 것 같습니다
'Programming > Go' 카테고리의 다른 글
| Go/Golang Test (2) | 2021.08.26 |
|---|---|
| Go/Golang Memory Management (16) | 2021.08.22 |
| Go/Golang Protobuf Compile Guide (0) | 2021.08.16 |
| Go/Golang Configuration (0) | 2021.08.16 |
| Go/Golang awesome-go (0) | 2021.08.11 |