

Go Memory에 이어 이번엔 Go Scheduler입니다
Go는 일반적인 프로그래밍 언어들과는 달리 goroutine이라는 형태를 사용합니다
우리는 goroutine으로 기존의 thread 방식보다 편리하게 concurrency를 구현합니다
뿐만 아니라 goroutine은 thread보다 가벼운 구조체이며 높은 성능을 자랑합니다
thread랑 goroutine은 뭐가 다른 걸까요?
단순히 goroutine만 아는 것보단 Go의 Scheduling을 이해해야 합니다
Memory 포스팅에서 잠깐 언급했듯이
Go는 Java의 JVM, .NET Framework의 CLR처럼
호스트 머신에 설치된 런타임을 이용하는 것이 아니라
생성되는 바이너리 파일에 작은 런타임을 포함합니다
해당 런타임이 바로 Go의 GC와 Scheduling을 수행합니다
(GC는 이전의 포스팅을 참고합시다)
Go/Golang Memory Management
이번엔 Go의 메모리 관리에 대해 정리해보려 합니다 Go가 1.17이 Release되는 현재 시점에서 해당 내용에 관해 국내에서 정리된 문서가 없는 것 같습니다 (몇가지 번역 문서는 존재하는것 같습니다)
syntaxsugar.tistory.com
재밌는 구조죠
또한, Go Scheduler 설계 덕분에 OS의 자원을 최소한으로 사용하면서
concurrency를 쉽고 강력하게 구현합니다
동시성 프로그래밍에 대해 먼저 간단히 살펴보고
Go Scheduler는 어떻게 동작하는지 알아보겠습니다
동시성 프로그래밍(Concurrency Programming)
CPU 기술이 진화하면서 CPU 코어의 개수를 늘리는
멀티코어 방식을 통해 성능을 향상하고 있습니다
하지만 코어의 수가 늘어나도 소프트웨어가 이를 활용하지
못하는 상황이 되었고, 이로 인해 동시성 프로그래밍이 중요해지게 됩니다
"Free lunch is over."
여기에도 유명한 말이 있습니다
프로그래머 및 져널리스트인 허브 셔터(Hurb Shutter)는
“공짜 점심은 끝났다.”(Free lunch is over)라는 말로
동시성 프로그래밍 시대를 표현했습니다
"성능 날먹 금지"
동시성 프로그래밍을 하기 위해 가장 잘 알려진 기술은 아시다시피 멀티쓰레딩입니다
하지만 thread는 오래된 기술이고 여전히 잘알려진 몇가지 문제가 존재하며 이 때문에
편리한 동시성 프로그래밍 기술이 계속 연구되고 있습니다
여기에 goroutine도 포함되어 있죠
하지만 goroutine도 일종의 thread 기반이기 때문에
동시성의 위험에서 벗어나진 못했습니다
(때문에 Go에서도 Actor 모델이 사용되곤 합니다)
하지만 goroutine은 가볍고 간단하며 빠릅니다(tradeoff)
여전히 훌륭하죠
Actor는 다음 기회에 포스팅해보도록 하고,
Go scheduler의 구조와 이를 기반으로 goroutine의 원리를 알아보겠습니다
Go Scheduler
goroutine이 뭐가 좋은지 빠르게 이해하려면
역시 thread와 비교하는게 빠를것 같습니다
0. goroutine VS thread
0.1 메모리 소비 측면
- goroutine
- 생성하는데 2KB의 스택 영역만 필요
- 필요에 따라 힙 저장 공간을 추가로 확보해서 사용
- thread(Java)
- 1MB의 스택 영역 사용(goroutine의 500배)
- thread 메모리 간의 보호 공간(guard page)이 필요
- 많이 생성할수록 사용할 수 있는 heap의 크기가 줄어듦 -> OOM(Out Of Memory) 발생 위험

0.2 설치와 철거 비용 측면
thread는 OS로부터 리소스를 요청하고, 끝난 경우 반환합니다
이 비용은 결코 작지 않기 때문에 thread pool 같은 방법들을 주로 이용합니다
goroutine은 이 비용이 매우 작기 때문에 이론상 수백만 개를 유지할 수 있습니다
(thread는 많아야 수만개?)
0.3 Context Switching 비용 측면
thread가 blocking되면 다른 thread가 그 자리를 스케쥴링해야 합니다
이를 Context Switching이라고 하는데
해당 thread가 실행중이던 '상황/문맥/context'를 저장해야지
다음 스케쥴링 기회에 다시 thread가 하던 작업을 수행할 수 있겠죠
이를 위해 thread가 바뀌기 전 모든 레지스터의 Save/Restore가 수행됩니다
- 16개의 범용 레지스터
- PC(Program Counter)
- SP(Stack Pointer)
- Segment 레지스터
- FP Coprocessor State
- AVX 레지스터
- 모든 MSR
- 등등
반면에 goroutine은 오직 3개의 레지스터만 사용합니다
- PC(Program Counter)
- Stack Pointer
- DX
쓰레드나 goroutine의 생성량이 많아질수록
context 저장/로드 비용 차이는 더 커지겠죠
물론 goroutine의 개수는 thread에 비해 많이 생성하는 편이지만
생성 비용이 매우 작기 때문에 thread와 비교할 정도가 아닙니다
그럼 thread와의 차이를 통해 goroutine이 얼마나 향상된 방법인지 대략 감을 잡았습니다
이제 어떻게 설계되었는지 살펴봅시다
1. Thread Model
goroutine은 사용자가 봤을 땐 thread와 차이가 없어 보이지만
내부적으론 일반적인 thread와 달리 M:N thread 모델을 사용하여
기존 thread 모델보다 가볍고 빠른 특성을 가집니다
thread 모델의 특징을 간단히 살펴봅시다
개발에서 thread는 실제 OS가 제공하는 OS thread를 추상화해 사용합니다
해당 추상화 thread와 OS thread 간의 매핑 방식에 따라
아래처럼 N : 1, 1 : 1, M : N 으로 나뉩니다
- N : 1

- 여러 thread가 하나의 OS thread를 통해 동작
- 커널의 도움 없이 App 수준에서 scheduling하므로
context-switching이 가볍고 빠름 - 멀티코어 활용 불가
- 1 : 1

- 1개의 thread는 1개의 OS thread와 매핑되어 동작
- context-switching이 커널에 의해 발생하여 비용이 크고 매우 느림
- 멀티코어 활용 가능
- M : N
- 여러 thread(goroutine)이 여러 OS thread를 통해 동작
- context-switching 빠름
- 멀티코어 활용 가능
- 구현이 어려움
Go는 Go Scheduler의 M : N 설계를 통해 Context Switching에서 장점을 갖도록 설계되었습니다
M : N 이 Go에서는 어떻게 구현되었는지 살펴봅시다
2. G, M, P 구조체
Go Scheduler는 G, M, P 라는 구조체를 이용해 M : N 모델을 구현합니다
Go Scheduler는 G, M, P라는 구조체를 갖고
GRQ(Global Run Queue), LRQ(Local Run Queue)를 이용하여
효율적으로 작업을 분배합니다
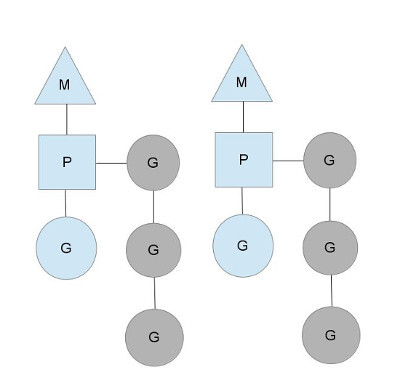
G : Goroutine - 우리가 아는 goroutine
M : Machine(OS Thread) - goroutine을 동작시킬 수 있는 OS thread
P : Processor(Logical) - OS Thread가 특정 goroutine을 실행시킬 수 있도록 매핑
(P는 사실상 context를 관리하므로 context라고 이해하면 편함)
(P의 개수는 GOMAXPROC라는 환경 변수로 설정 가능, 기본으론 CPU 코어 개수로 설정)
회색 G는 대기 중이며 스케줄 될 준비가 되어있는 goroutine입니다
회색 goroutine이 대기 중인 queue를 run queue라고 합니다
- P가 가지고 있는 run queue : Local Run Queue(LRQ)
- P에 지정되지 않은 run queue : Global Run Queue(GRQ)
해당 queue에 실행될 goroutine을 순차적으로 쌓아두고
goroutine을 queue에서 꺼내어(polling) 한차례의 작업을 수행하거나 system call이 수행되는 경우
다음 goroutine을 꺼내 실행하고, 새로 추가되는 작업은 queue의 가장 끝에 추가됩니다
(goroutine은 한 번에 최대 10ms 동안 동작하며 동작한 이후 GRP에 저장됩니다)
(goroutine 생성 시, LRQ가 꽉 찬 상태면 GRQ에 저장됩니다)
[System call]
/*
시스템 명령을 수행하기 위한 커널 함수 호출을 의미
작업 수준에 따라 blocking, non-blocking으로 나뉘며
blocking 수행 시, 완료될 때까지 해당 thread는 blocking 됩니다
이 때문에 커널의 접근 비용은 매우 크며 보통 디바이스 드라이버(특히, I/O) 때문에
어쩔 수 없이 사용됩니다
*/
이후 작업이 완료된 G는 free list에 들어가 나중에 재사용되며
M이나 P도 사용하지 않게 되면 free list에 보관되며 필요해질 때 재사용하여
생성 비용을 절감합니다
2.0 LRQ, GRQ
LRQ와 GRQ가 따로 있는 이유는 뭘까요?
GRQ만 사용할 경우 모든 P가 하나의 GRQ에 접근하게 되어
critical section을 보호하기 위한 mutex를 사용하게 됩니다
이는 goroutine creating, destroying, scheduling에 모두 lock이 생겨
성능 저하의 원인이 됩니다
이 때문에 Go는 P마다 LRQ를 사용해 GRQ의 접근을 줄여 이러한 문제를 최소화하였습니다
그리고 LRQ의 queue는 일반적인 queue의 형태와는 조금 다릅니다

그림에서 보다시피 FIFO와 size가 1인 LIFO로 구성되며
goroutine이 enqueue되는 경우, LIFO에 먼저 들어오고
goroutine이 dequeue되는 경우, LIFO에서 먼저 나가는 형태입니다
FIFO보다 LIFO보다 우선도가 높죠
그러면 FIFO의 goroutine들은 불공평하게 대기하는데 왜 이렇게 설계했을까요?
goroutine에 Locality를 부여하기 위해서입니다
예를 들어 goroutine A가 다른 goroutine B를 생성하는 경우가 있습니다
A가 B의 종료를 기다리는 로직이라면 B가 빠르게 마무리되어야 A의 성능이 높아지며
Cache 관점에서도 A, B goroutine은 동일한 processor에서 처리되는 게 좋습니다
(processor의 캐시, 스택 등을 동일하게 사용 가능하므로)
따라서, 이러한 성능상의 이점을 고려하여 A의 goroutine이 수행 중에 B를 생성하면
B가 동일한 processor에 생성되어 바로 실행되도록 위와 같은 queue 구조를 사용합니다
이제 몇 가지 Go Scheduling의 상황별 동작을 살펴보겠습니다
2.1 Blocking System Call(synchronous system call)

goroutine 동작 중에 I/O나 cgo(go에서 C 함수를 호출) 등의 처리로
위의 그림처럼 M0에 blocking이 발생합니다
Go Scheduler는 P의 다른 goroutine이 block되는 것을 막기 위해
M0과 M0을 blocking시킨 goroutine을 함께 분리해둡니다(hand off)
M이 떨어진 P는 free list에 있는 M을 불러오거나 없는 경우 M을 새로 만들어
다른 goroutine을 실행하여 blocking이 없던것 처럼 처리하게 됩니다
(기존에 존재하는 M을 가져오는 경우 Context Switching이 더 빠름)
(이 과정에서 M을 생성하면 thread가 추가적으로 생성되며
go 프로세스 실행 시, 시스템에 thread 개수가 늘어나면
이러한 원인으로 파악할 수 있습니다)
system call이 완료된 goroutine은
기존 P의 local run queue(LRQ)에 다시 들어가거나
Global run queue(GRQ)에 들어갑니다
M에 P로 나뉘어 동작하기 때문에 위와 같이 멋진 처리가 가능합니다
다시 정리하면 실행 중인 thread가 blocking된 경우,
blocking된 thread는 P에서 분리시켜 background에서 진행시키고
P와 새로 연결되는 다른 thread로 해당 state를 그대로 넘겨
다른 goroutine을 멈춤없이 처리할 수 있도록 보장되어 있으며
이러한 구조 때문에 GOMAXPROC 값이 1이더라도
Go는 내부적으로 멀티스레드로 동작합니다

이제 그림과 같은 goroutine의 모델을 이해할 수 있게 되었습니다
이러한 구조를 M:P:N 이라고도 합니다
2.2 Non-Blocking System Call(asynchronous system call)

이번엔 Network I/O 같은 Blocking이 되지 않는 system call의 경우입니다
Network I/O 같은 경우 OS로부터 완료 signal을 받기 전까지 M은 그대로 두고
goroutine만 따로 분리하여 Netpoll이라는 구조체에 둡니다
- Netpoll은 추상화이며 linux에선 epoll, mac에선 kqueue, windows에선 iocp를 사용
M은 LRQ에서 다른 Goroutine을 가져와 동작을 시작하며
비동기 system call을 완료한 goroutine은 다시 기존 P의 LRQ로 들어옵니다
이러한 경우는 네트워크 응답 대기나 time.Sleep을 사용한 예시의 경우입니다
2.3 Work Stealing

규칙은 아래와 같습니다
runtime.schedule() {
// only 1/61 of the time, check the global runnable queue for a G.
// if not found, check the local queue.
// if not found,
// try to steal from other Ps.
// if not, check the global runnable queue.
// if not found, poll network.
}
M-P 쌍이 수행할 goroutine이 LRQ에 없는 경우,
우선적으로 GRQ에서 G가 있는지 확인하고,
없는 경우, 다른 P의 LRQ의 일을 뺏어옵니다
이때 가져오는 양은 LRQ의 절반입니다
(생성된 지 3ms 이내의 goroutine은 건드리지 않습니다)
이를 통해 병목 현상을 없애고 OS 자원을 분산시켜 효율적으로 사용합니다
2.4 Fairness
모든 goroutine은 공평하게 실행되어야 합니다
과연 Go Scheduling은 어떻게 Fairness를 수행하고 있을까요?
Go Scheduler에는 4가지 규칙이 있습니다
- Thread(preemption)
- 무한 루프로 goroutine이 thread를 독점하지 못하도록
goroutine이 10ms(soft-limit) 이상 실행되는 경우
timeout이 발생하고 강제 선점(preemption)하여 GRQ로 이동- Preemptive : >= 1.14
- Non-Preemptive : < 1.14
- 무한 루프로 goroutine이 thread를 독점하지 못하도록
- LRQ(time slice)
- LRQ 부분에서 설명하였듯이 LRQ는 FIFO와 LIFO로 이루어져 있음
- 2개의 goroutine이 서로를 번갈아서 실행하면
LIFO에 2개만 우선적으로 번갈아서 저장되고 실행되므로
FIFO의 goroutine은 영원히 실행되지 않을 수 있음 - 이를 막기 위해 LIFO 영역에서 goroutine이 생성되는 경우
time slice inheritance로 time이 초기화되지 않고 상속되어
최대 10ms(soft-limit) 만큼 timeout 처리를 수행
- GRQ(check once)
- LRQ에 존재하는 goroutine이 없는 경우에만 Work Stealing으로
GRQ의 goroutine을 처리하면 GRQ는 계속 처리되지 않을 수도 있음 - Go Scheduler는 "61"번째 scheduling을 수행할 때
LRQ보다 GRQ에 있는 goroutine을 먼저 확인하고 실행하도록 함
- LRQ에 존재하는 goroutine이 없는 경우에만 Work Stealing으로
- Network Poller(background thread)
- 독립된 Background thread로 OS 레벨에서 동작을 보장 받음
Overview 정리
위의 내용을 아래 그림으로 정리할 수 있습니다
한번 보시고 다시한번 정리해하기에 좋겠습니다

전반적인 구조와 흐름을 알았으니
G, M, P 구조체를 좀 더 자세히 정리해보겠습니다
G 구조체
- Goroutine을 표현
- 기본적으로 2KB의 stack 할당, 필요한 경우 추가 할당
- runtime scheduling의 기본 단위
- context switch를 위한 stack pointer 관련 데이터 보유
- OS thread 처럼 goroutine의 상태(state)에 대한 데이터 보유
- 일반적으론 Runnable, Waiting, Executing 세 가지 상태로 알려졌지만
실제 코드에는 아래와 같이 상세하게 분류됨(https://github.com/golang/go/blob/9f69a44308f4f9cbdae68925202dfef2027a7d20/src/runtime/runtime2.go#L14)- Idle : 생성되었으나 초기화되지 않음
- Runnable : run queue에서 실행되기를 대기
- Syscall : system call 수행 중인 goroutine
- Waiting : runtime에서 block된 상태(by system call, channel, mutex, etc)
- Dead : 막 초기화되었거나 goroutine이 종료되어 free list에 들어간 상태
- Scan : GC가 STW(Stop The World)한 후, goroutine stack scan 중
- Executing : 실행 중인 상태
- 일반적으론 Runnable, Waiting, Executing 세 가지 상태로 알려졌지만
M 구조체
- Machine, OS Thread(Worker Thread)를 표현
- P 구조체의 LRQ로부터 G 구조체를 할당받아 실행
- Application Level의 goroutine과 OS thread를 연결
- thread의 handle을 담고 있는 데이터와 현재 실행 중인 goroutine, 그리고 P 구조체를 가리키는 포인터를 가짐
P 구조체
- Logical Processor
- M이 할당되어 실행되는 context
- 최대 GOMAXPROC개를 가질 수 있음(논리 core 개수)
- LRQ를 가져 goroutine을 하나씩 꺼내 M에 할당
Go Scheduler의 내용을 정리했습니다
이러한 설계를 통해 I/O Bound가 발생하여도
정해진 수의 P와 goroutine 처리를 유지하는 처리는
우아하고 세련되어 보입니다
특히 성능시험을 하다 보면 goroutine과 thread 개수의 동작이 이해 안 될 때가 있는데
이러한 내용을 미리 파악하면 더 좋은 선택과 분석을 할 수 있을 것입니다
참고로 모두 Go runtime 소스코드와 공식 문서에서 확인할 수 있는 내용들입니다
Go는 이래서 좋네요
runtime.go
GitHub - golang/go: The Go programming language
The Go programming language. Contribute to golang/go development by creating an account on GitHub.
github.com
[Reference]
https://blog.puppyloper.com/menus/Golang/articles/Goroutine%EA%B3%BC%20Go%20scheduler
https://ssup2.github.io/theory_analysis/Golang_Goroutine_Scheduling/
https://medium.com/a-journey-with-go/go-goroutine-os-thread-and-cpu-management-2f5a5eaf518a
https://rokrokss.com/post/2020/01/01/go-scheduler.html
https://cppis.github.io/golang/common/2020/10/23/whats.golang.scheduler.go.scheduler.html
https://www.ardanlabs.com/blog/2018/08/scheduling-in-go-part1.html
https://medium.com/@ankur_anand/illustrated-tales-of-go-runtime-scheduler-74809ef6d19b
https://www.ardanlabs.com/blog/2018/08/scheduling-in-go-part2.html
https://www.ardanlabs.com/blog/2018/12/scheduling-in-go-part3.html
'Programming > Go' 카테고리의 다른 글
| Go/Golang HTTP 성능 튜닝 (0) | 2021.09.24 |
|---|---|
| Go/Golang Dependency Injection (13) | 2021.09.10 |
| Go/Golang Test (2) | 2021.08.26 |
| Go/Golang Memory Management (16) | 2021.08.22 |
| Go/Golang Protobuf Compile Guide (0) | 2021.08.16 |