

기존 포스팅에서 종종 Actor를 언급을 했습니다.
Akka Framework에 대해 포스팅하려다가
Actor가 무엇인지, 왜 필요한지를 먼저 정리해봤습니다.
1. Background
CPU Clock 성능 진화의 한계 도달
(무어의 법칙은 무너진 지 오래)
CPU는 현대에와서는 질보다 양적 증가로 이어져 왔습니다.
양적 증가로 인해 여러개의 CPU를 잘 사용하여 하드웨어의 성능을
따라갈 수 있도록 소프트웨어에서 병렬 처리가 필요해졌습니다.
이를 보고 유명한 프로그래머이자 져널리스트인
허브 셔터(Hurb Shutter)가 아래와 같은 말로
동시성 프로그래밍 시대를 표현했습니다.
Free launch is over
- Hurb Shutter -
공짜 점심은 끝났다. (성능 날먹은 끝났다.)
소프트웨어적인 노력이 필요해졌다라는
뜻으로 생각하면 됩니다.
워낙 대표적인 표현이라 Go Scheduling 포스트에서도
서론에 잠깐 언급했었죠.
Go/Golang Scheduling
Go Memory에 이어 이번엔 Go Scheduler입니다 Go는 일반적인 프로그래밍 언어들과는 달리 goroutine이라는 형태를 사용합니다 우리는 goroutine으로 기존의 thread 방식보다 편리하게 concurrency를 구현합니다..
syntaxsugar.tistory.com
먼저 병행성과 병렬성에 대해 정리하고 시작하겠습니다.
1.1 병행성(Concurrency) VS 병렬성(Parallelism)
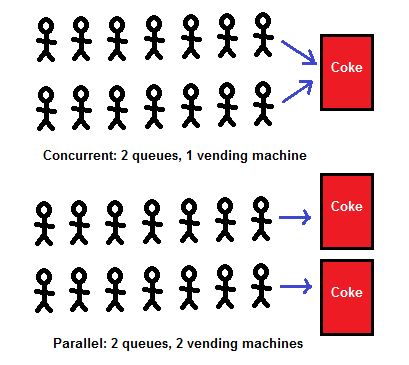

- 병행성(Concurrency)
- 코어가 한 개여도 어느 순간 동시에 동작하는 것처럼 보이지만
동시가 아니라 한 개의 코어가 빠르게 번갈아 수행하는 것임 - 소프트웨어 수준의 처리로 구현
- 코어의 수가 2배가되어도 2배만큼 빨라질 수 없음(암달의 법칙)
- 예) Thread, Actor 등
- 코어가 한 개여도 어느 순간 동시에 동작하는 것처럼 보이지만
- 병렬성(Parallelism)
- 실제로 동시에 작업이 처리됨
- 멀티코어에서만 가능하며 코어의 수만큼 빨라짐
- 하드웨어 + 소프트웨어(병렬 알고리즘) 처리로 구현
- 두 가지의 작업 형태가 존재
- 데이터 병렬성 : 하나의 작업(Task)의 전체 데이터를 서브 데이터로 나눠 처리
- 작업 병렬성 : 서로 다른 작업을 동시에 처리
- 두 가지의 메모리 접근 방식이 존재
- 공유 메모리(Shared Memory)
- 여러 프로세서가 메모리 공유
- 접근 속도 동일
- 분산 메모리(Distributed Memory)
- 다른 프로세서의 메모리에 접근해야 할 수 있기 때문에 접근 속도 다름
- 공유 메모리(Shared Memory)
- 오버헤드 존재
- Communication : 작업을 나누어 전달, 결과를 통합
- Load Balancing : 코어별로 동등하게 작업을 나눠야 함
- Synchronization : 크리티컬 섹션에 대한 접근 문제
- 예) OpenMP, CUDA 등
위와 같이 명확하게 구분할수 있지만
별 구분 없이 쓰이기도 합니다.
이 포스팅에선 병행성에 대해서만 다룹니다.
병렬성은 나중에 다루게될지 모르겠네요.
병행성으로도 멀티코어 활용이 가능하며
멀티쓰레드 등의 활용은 프로그래밍의 기본적인 내용이 되었습니다.
1.2 쓰레드(Thread)
동시성 프로그래밍에서 중요한 것은 성능과 안정적인 처리 두 가지입니다.
일반적으로 개발자들은 멀티쓰레드로 동시성 처리를
해왔지만 쓰레드는 오래된 기술이고 안정성 측면에서
잘 알려진 몇 가지 문제가 존재합니다.
복잡하고 어려우며 잠재적인 버그 발생의 원인
- 쓰레드 간 공유되는 데이터는 개발자가 관리해야 함
- 비결정성(Non-Deterministic) 때문에 버그가 발생하여도
재현하기도, 디버그 하기도 어려움- 운영체제가 쓰레드 실행을 관리
- 공유 데이터의 처리
- 같은 데이터에 동시 접근하는 것을 막기 위해(Data Race)
mutex lock 등의 처리가 필요 - dead lock, starvation, 누락된 처리 등까지 고민해야 함
- 같은 데이터에 동시 접근하는 것을 막기 위해(Data Race)
대표적으론 위와 같이 존재하며
애초에 쓰레드만의 문제라기보단 병렬 처리 자체가
비결정적이기 때문에 사람의 머리로 예측하기 어렵습니다.
여기에 공유 데이터와 크리티컬 섹션의 처리를 생각하면
성능 이슈까지 존재하게 됩니다.
쓰레드를 사용하는 대부분의 프로그램들은 버그로 가득 차 있다.
- Havoc Pannington-
이러한 문제들의 최선의 해결책으로 Actor 모델이 사용되고 있습니다.
2. Actor Model
Actor는 어떻게 비동기, 동시성 처리를 가능하게 할까요?
객체 지향에서 '모든 것은 객체(Object)다'라고 생각하는 것처럼
Actor 모델에서는 '모든 것은 액터(Actor)다'라는 철학이 있습니다.
객체를 사물에 비유하듯이
Actor라는 것도 추상적인 개념이기 때문에
사람이라고 비유하면 이해하기가 쉽습니다.
2.1 Concept
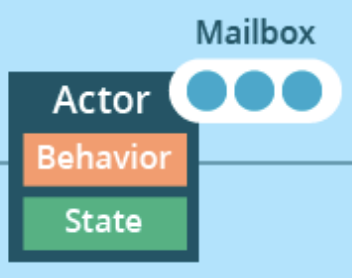
쓰레드라는 구조가 동작하는 것처럼
Actor라는 구조가 있습니다.
위 그림과 같이 Actor는 세 가지로 구성됩니다.
- Behavior : 행동
- State : 상태(변수)
- Mailbox : 수신함(큐)
쓰레드가 여러개로 동작하듯이
Actor도 여러개가 동작합니다.
init, ready, closed 등의 상태를 정의할 수 있고
매순간 정의된 상태 중 하나의 상태를 가집니다.
(상태를 변수로 갖고 있다고 생각하면 됩니다.)
Actor 간에는 메시지를 주고 받을 수 있습니다.
메시지는 여러 종류를 정의할 수 있습니다.
(메시지는 구조체 형식이라고 생각하면 됩니다.)
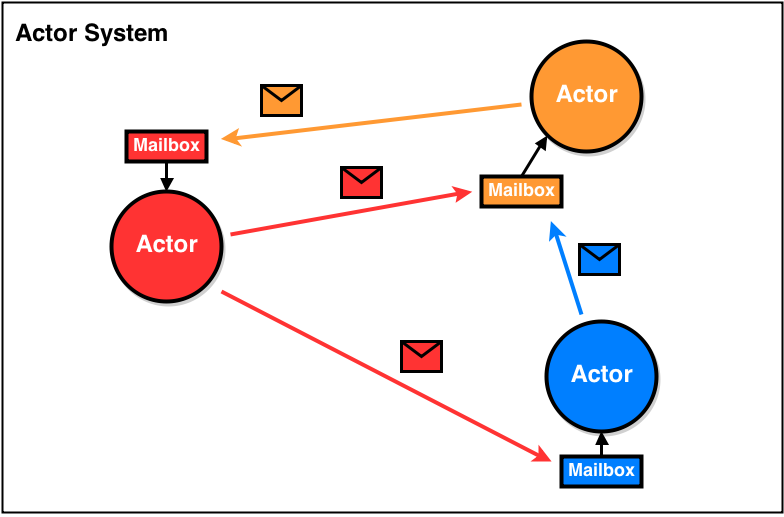
Main문에서 Actor를 지정해 메시지를 보내면
해당 Actor의 수신함에 메시지가 들어가고
수신한 Actor는 이벤트가 발생해
받은 순서대로 메시지를 확인합니다.
메시지를 수신한 Actor는 메시지 종류를 구분합니다.
구분하여 적절한 행동을 취하도록 정의합니다.
switch 문을 생각하면 쉽습니다.
switch 메시지 {
case A: 행동X 수행
case B: 행동Y 수행
case C: 행동Z 수행
default: 모르는 메시지에 대한 행동 수행
}
쓰레드가 run되면 수행할 행동을 정의하듯이
Actor가 메시지를 받으면 수행할 행동을
이러한 switch문 형식으로 정의한다고 이해하면 됩니다.
다시 정리해보겠습니다.
Actor는 Behavior(행동), State(상태), Mail Box(수신함)으로 구성됩니다.
- State는 메시지를 수신하였을 때, Actor 자신만 변경 가능
- Mail Box에 쌓인 메시지는 순서대로 처리함
- 수신한 메시지에 따라 Behavior를 결정하여 실행
Behavior는 다음과 같습니다.
- 자신의 State 변경
- Child Actor 생성 및 제거
- 다른 Actor에 메시지 전송
- + 그 외 Actor가 수행하길 원하는 모든 동작
Object와 Actor는 아래와 같은 측면에서 비교될 수 있습니다.
- Object는 Method를 호출하여 동기적으로 작업이 수행
- Actor는 Message를 보내어 비동기적으로 Behavior를 수행
동기?
- 기본적인 프로그램 방식
- 이전에 수행한 작업이 완료되어야 다음 작업 수행
- 이전 작업을 완료될 때까지 멈추므로 Blocking 방식이라고도 함
비동기?
- 쓰레드 등을 이용한 방식
- 작업을 동시에 처리
- 작업을 기다리지 않고 각자 주어진 일을 하므로 Non-Blocking 방식이라고도 함
공식적으로는 아래와 같이 설명되어 있습니다.
Actor는
- 다른 Actor에게 유한 개수의 메시지를 보낼 수 있다.
- 유한한 개수의 새로운 Actor를 만들 수 있다.
- 다른 Actor가 받을 메시지에 수반될 행동을 지정할 수 있다.
- 이러한 작업은 동시적으로 진행되고 정해진 순서는 없다.
칼 휴이트 (Carl Hewitt), 1973
위의 내용을 정리해봅시다.
- Actor는 독립적인 메모리 공간을 갖는다.
- Actor 간의 상호작용은 메시지를 통해 이루어진다.
라는 기본적인 개념을 가집니다.
이해를 위해 굳이 쓰레드와 비교하자면
1. 쓰레드처럼 각 Actor도 자신만의 메모리 공간을 가짐
2. 전역변수 등 공통으로 접근하는 값을 직접 변경해
다른 쓰레드에 영향을 미칠 수 있는 쓰레드와 달리
Actor는 다른 Actor로 메시지를 보내는 방법으로만
영향을 미칠 수 있음.
(Actor 외부에서 직접 변경하려하면 보통은 강제로 에러를 발생시킵니다.)
이 정도면 어렵지 않게 정리된 것 같습니다.
아직 감이 안잡혀도 아래의 그림이 이해는 되실겁니다.
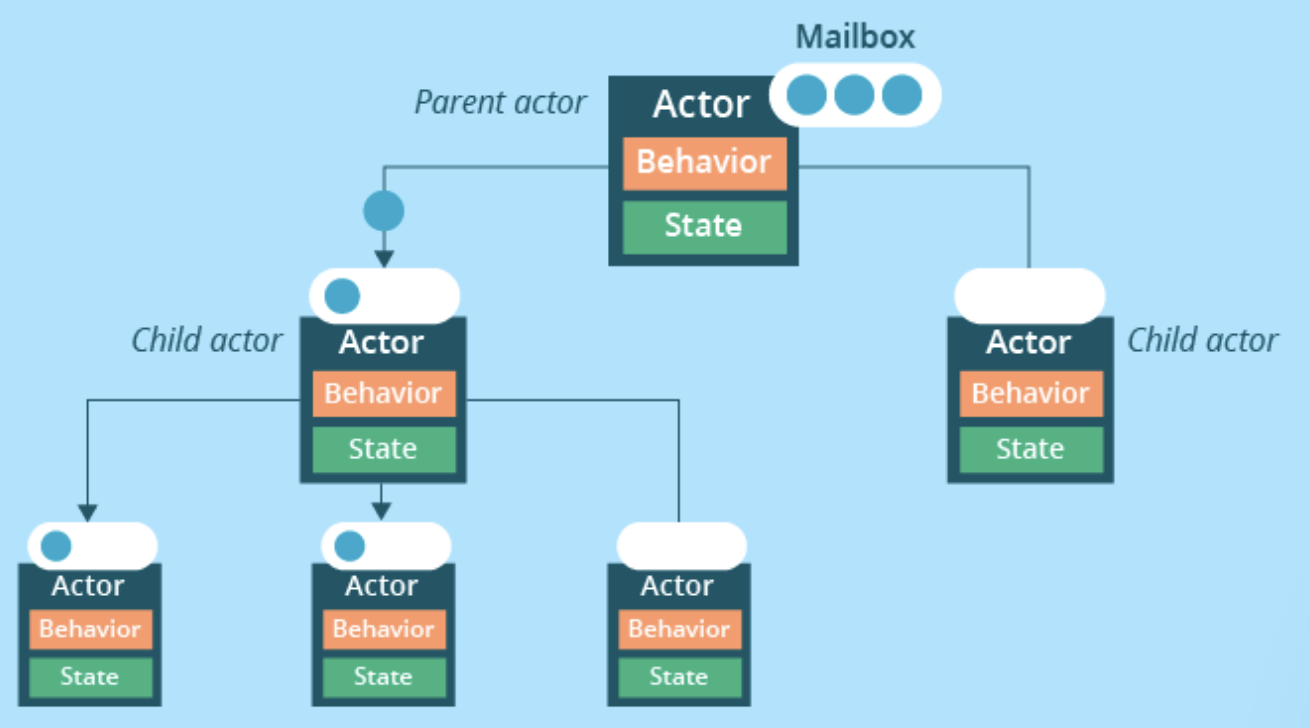
메모리를 공유하지 않으니 공유 데이터의
처리를 고민할 필요가 없어지는 것이죠.
우리는 머리 아프게 이 이상으로
복잡한 케이스를 고민할 필요가 없습니다.
각 Actor만 잘 정의하면 아래와 같이
복잡한 형상이 되더라도 문제없이 동작합니다.

Actor가 수신한 메시지는 아래 그림과 같이 쌓이게 되고
처리 중인 메시지가 끝나면 다음 메시지를 꺼내 처리합니다.
메시지는 순서대로 처리됩니다.
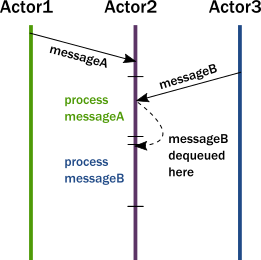
Actor의 내부 동작은 쓰레드풀로 구현되어 있습니다.
하지만 Actor마다 하나의 쓰레드가 할당되는 개념이 아니라
주어진 쓰레드풀에서 필요한만큼 필요한 순간에
유동적으로 사용하는 방식입니다.
다시 말해 Actor는 쓰레드를 사용자가
직접 구현하지 않도록 하는것이 목표입니다.
사용자는 동시성 처리를 Actor에 맡기고
서비스 로직에만 집중하도록 하는것입니다.
Akka 등은 이러한 정신을 충실히 반영하고 있습니다.
즉, 쓰레드는 Actor 시스템이 내부적으로, 알아서, 훌륭하게 사용하고
튜닝 요소를 제공해 이를 간접적으로 조정할 수 있도록 하였습니다.
정확히 어떤 쓰레드가 어느순간에 어느 Actor로써 동작할것인지는
꽤나 복잡하며 Akka나 Erlang의 내부 구현을 알아야 합니다.
Akka의 경우 꽤나 자세히 설명이 되어 있기 때문에 궁금하면
Akka Dispatcher를 찾아보기 바랍니다.
(사용할 쓰레드풀의 크기는 직접 지정할수 있습니다.)
2.2 Fault Tolerance
Acto는 Fault Tolerance 한 특성까지 가집니다.
Actor는 "고장 나도록 내버려둔다('let it crash')"는 철학을 갖고 있습니다.
가능한 모든 문제 상황들을 예상하고 그것들을 다 다룰 수 있는 방법을 마련하는
방어적인 프로그래밍을 할 필요가 없도록 만들어줍니다.
(Cloud의 Container, Kubernetes의 Pod와 비슷한 그것이죠.)
고장 나면 어떻게 처리하길래 문제가 없을까요?
Actor는 Supervision이라는 개념을 사용합니다.
각 Actor는 사용자가 원하는 자유로운 방식으로 구현되어 사용될 수도 있지만
일반적으로 Supervision 한 패턴으로 구현이 됩니다.
Supervision이 뭘까요?
각 Actor는 Child Actor를 생성하고 메시지를 보낼 수 있습니다.
Child Actor를 생성한 Actor는 해당 Child의 Parent Actor가 됩니다.
Child Actor에서 문제가 발생하면 이를 Parent Actor에 통보하고,
Supervisor로써 적절한 전략으로 처리합니다.
여기서부터 상세한 사항은 시스템에 따라 전략이 다를 수 있습니다.
가장 널리 알려진 Akka Actor를 예로 설명하겠습니다.
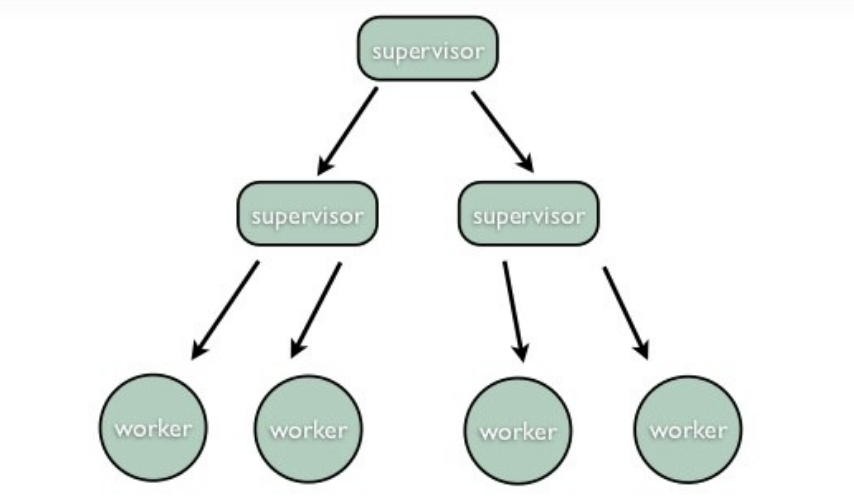
Parent Actor는 Supervisor로써 Child Actor를 생성해 업무를 나누어주고,
Child Actor의 실패(예외 등)를 Handling 하는 역할을 수행합니다.
Child Actor가 실패를 감지했다면 자신의 하위 Actor들을 모두 Stop 하고,
Parent에게 실패를 알리는 메시지를 전달합니다.
Supervisor는 실패 메시지를 4가지 전략(Streategy)을 옵션으로 처리할 수 있습니다.
- Resume the subordinate, keeping its accumulated internal state
Child Actor 동작 재개 - Restart the subordinate, clearing out its accumulated internal state
Child Actor의 State를 초기화하여 재시작 - Stop the subordinate permanently
Child Actor 제거 - Escalate the failure, thereby failing itself
실패를 확장하여 Supervisor 자신도 실패 처리
이를 아래와 같이 예외 별로 처리할 수도 있습니다.
(Akka 예시입니다. 개인적으로 꽤 마음에 드는 처리입니다.)
import akka.actor.OneForOneStrategy
import akka.actor.SupervisorStrategy._
import scala.concurrent.duration._
override val supervisorStrategy =
OneForOneStrategy(maxNrOfRetries = 10, withinTimeRange = 1 minute) {
case _: ArithmeticException => Resume
case _: NullPointerException => Restart
case _: IllegalArgumentException => Stop
case _: Exception => Escalate
}
이러한 형상으로 Actor는 자가 회복하는 시스템을 가질 수 있습니다.
Supvisor가 crash 된 Actor를 안정된 상태로 되돌리기 위한 작업을 할 수 있기 때문이죠.
(가장 흔히 채택되는 전략은 Actor를 재시작하여 초기 상태로 만드는 것입니다.)
Actor의 핵심 정신은 Correctness입니다.
위에서 설명한 내용은 예시로써 기본적인 Actor의 처리이며
실제로는 안정적인 처리를 위해 더 상세한 내용들을 고려하고 있습니다.
제가 이 포스팅에서 일부만을 설명하는 것으로 오해를 유발하거나
정확한 내용을 파악하지 못하게 할 수 있다고 생각합니다.
실제로 사용하거나 더 자세한 사항을 알기 위해서는
해당 Actor의 문서나 코드를 참고하기 바랍니다 :)
2.3 Distribution
Actor의 주목할 만한 또 하나의 측면은 자신이 메시지를 보내는 대상이
로컬에 있는지 또는 다른 노드에 있는지 전혀 신경 쓸 필요가 없다는 점입니다.
Actor는 우편함과 상태를 갖고 메시지에 응답할 필요만 있는데 그 Actor가
어떤 머신에서 도는 게 문제가 될까요?
보낼 메시지만 제대로 도착한다면 문제가 없습니다.
즉, 여러 대의 컴퓨터가 상호작용하고 한 대가 죽은(fail) 경우 다른 하나가
그의 회복을 돕는 시스템을 구성하는 것도 문제가 없습니다.
Akka를 예로 간단히 살펴보겠습니다.
Akka의 각 Actor는 유니크한 구분을 위해 path 방식의 Identity를 가집니다.
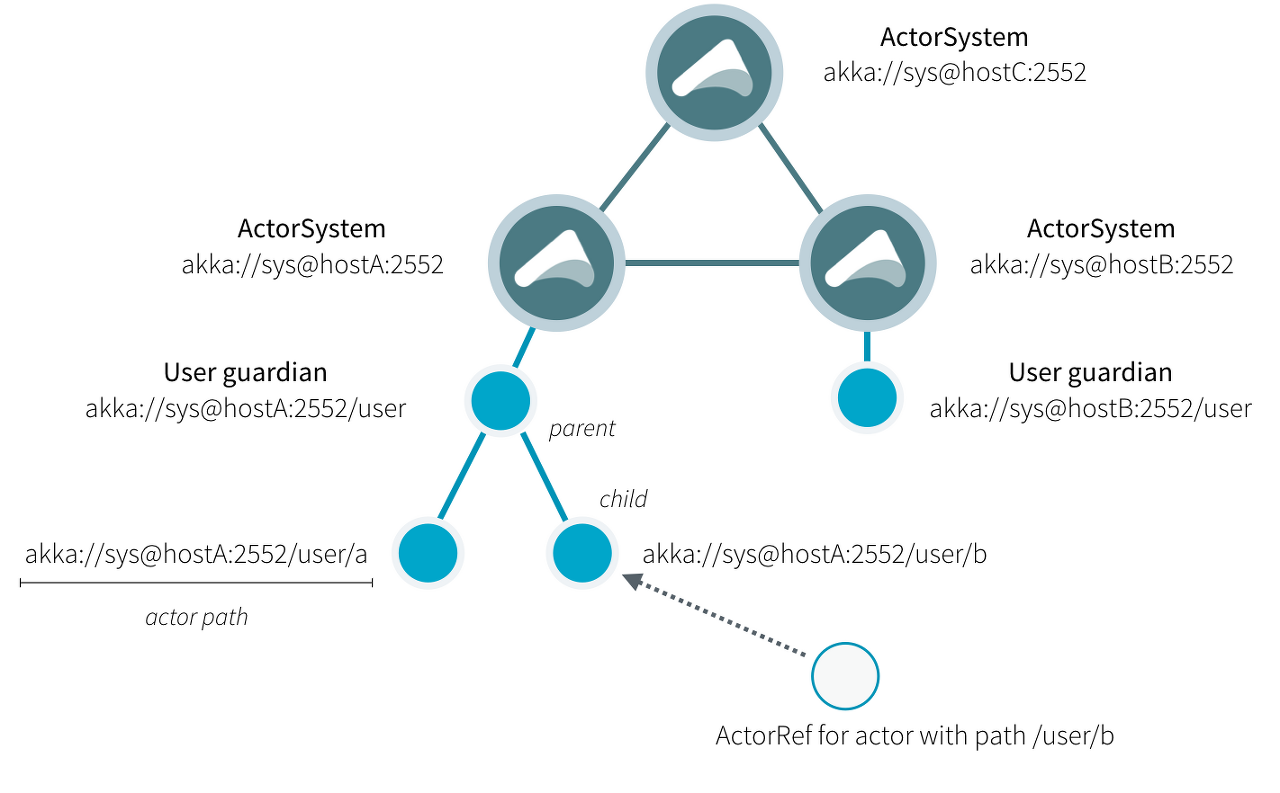
애초에 REST API처럼 URL 기반의 Identity를 갖기 때문에 이해하기 편합니다.
Remote의 Actor에 메시지를 보내어 상호작용하는데 문제가 없습니다.
이러한 구조 때문에 Clustering, Sharding 등의 처리도 용이하며 Akka에서 지원하고 있습니다.
3. Drawback
Actor의 단점은 어떨까요?
- 구현이 각 Actor 별로 퍼져있어 코드가 읽기 어려워질 수 있다.
- 공유하는 리소스 없이 모든 상호작용이 메시지로 동작하기 때문에 통신 비용에 의한 성능 문제가 발생할 수 있다.
개인적인 의견으로는 사실 Actor 자체의 커다란 단점을 찾기 애매합니다.
전문가들과 학문적으로도 많이 고려된 모델이기 때문에 다들 단점을
언급하기에 조심스럽다는 느낌까지 듭니다.
안정성도 안정성이지만 기본적으로 동시성 처리의
주목적은 성능이기 때문에 가장 큰 이슈는 아무래도 성능이겠죠.
성능예측이 간단하지 않은 이유 중 하나는 CPU와 쓰레드의 상관관계 때문입니다.
쓰레드가 무조건 많다고 성능이 좋아지지 않으며 특정 쓰레드 개수를 초과하는 경우
성능이 하락합니다.(context-switcing 등의 overhead)
Actor도 내부적으로 쓰레드를 사용하여 구현되어 있습니다.(Actor is not magic.)
하나의 Actor가 동작할 때 하나의 쓰레드가 할당되어 동작합니다.
(단, Actor가 동작하지 않는 경우, 휴식 상태로 들어가며 쓰레드가 할당되지 않습니다.)
쓰레드 최적화가 이루어지지만 통신 비용이 클것이라 생각이 들어서
특정 상황을 제외하고는 성능이 조금 떨어질 수밖에 없다고 생각이 드는데요.
정리하면서 저도 궁금해져 찾아보는데 생각한 내용을 찾기 힘드네요.
가장 괜찮은 문서는 Denis Kroeb의 Benchmarking Akka입니다.
현재 아래 링크로 받아 볼 수 있습니다.
https://scripties.uba.uva.nl/download?fid=679533
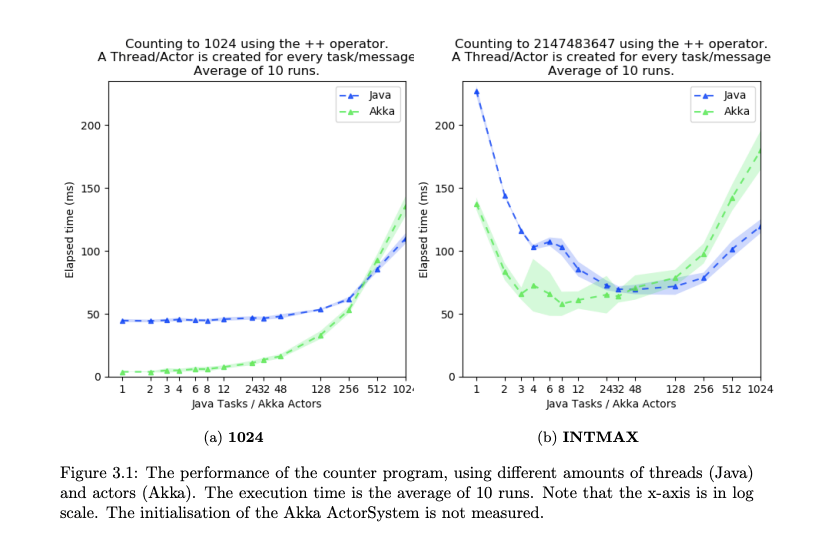
논문을 대강 봐서는 초기화 비용을 제외하고서 비교했을 때
쓰레드의 개수가 많아지지 않는 경우 대부분의 상황에서
Actor가 더 잘 나오는 것으로 보입니다.
크리티컬 섹션이 많은 구간에선 Actor가 더 잘 나올 것이라 생각했는데
단순 Couting으로 계산한 것인데도 이러한 결과가 나왔습니다.
아마 Actor 구현 자체로 내부에 쓰레드풀을 포함하고 있고
쓰레드는 쓰레드 생성비용 까지 포함되어 측정되었기 때문이라고 생각이 드는데
해당 실험이 Actor에 의해 동작하는 실제 쓰레드 개수와 쓰레드풀 방식과 비교하지 않은 것이 아쉽네요.
위에서 언급했듯이 Actor는 하나 당 하나의 쓰레드가 무조건 할당되는 방식이 아니기 때문에
생성 비용에서 훨씬 더 가벼울 수밖에 없습니다.
쓰레드는 보통 쓰레드풀을 사용하기 때문에 위의 결과가
정확히 성능 비교를 하기엔 어렵다고 생각이 들지만
최적의 쓰레드양을 모르는 상태에서 쓰레드 생성 비용을
감수하는 것보다는 Actor를 사용하는 것이 성능 측면에서도 유리하다고 볼 수 있겠습니다.
자세한 부분은 저도 논문을 정독해봐야겠습니다.
Actor도 성능을 튜닝할 수 있는 부분이 많기도 해서
시간 나면 정독하면서 직접 실험도 해볼까도 생각 중입니다.
Ruby를 만든 Yukihiro Matsumoto는 인터뷰 중에 이런 말을 했다고 합니다.
Bruce : 그때(루비를 만들었을 당시)로 돌아간다면, 어떤 기능에 변화를 주고 싶으세요?
Matz : 쓰레드를 없애고 Actor나 또는 진보된 형태의 동시성 기능을 추가했을 거예요.
유독 동시성 처리 관련해서 유명한 말이 많네요ㅎㅎ
그만큼 동시성 처리가 어렵고 많은 기술자들이 고민하는 분야이기도 하고
Actor가 많이 고려되는 모델입니다.
저도 그랬지만 Actor는 사실 처음 접하면 익숙하지 않은 방식인 건 사실입니다.
상세하게 익히는데 시간이 걸릴 수도 있지만 Correctness만큼은 확실하게 보장하는 모델입니다.
Erlang과 Scala의 Akka에서 Actor 모델을 채택하고 있으며
특히 Akka는 전문가들에 의해 굉장히 잘 설계된 Actor라 평 받고 있습니다.
(Akka를 사용하면 코드가 지저분하다는 지적이 있긴 하지만...)
특유의 안정적인 동작 덕분에 Go에서도 종종 사용되고 있습니다.
GitHub - asynkron/protoactor-go: Proto Actor - Ultra fast distributed actors for Go, C# and Java/Kotlin
Proto Actor - Ultra fast distributed actors for Go, C# and Java/Kotlin - GitHub - asynkron/protoactor-go: Proto Actor - Ultra fast distributed actors for Go, C# and Java/Kotlin
github.com
다음 Actor 포스팅에서는 Actor를 사용해서 Best Example을
만들어 볼까 하는데 Go의 Actor를 사용할지 고민이 되네요.
요즘 Go에 빠져서 Go의 동시성에
Channel, Goroutine, Actor를 비교하고 싶은 욕구가 듭니다.
'Programming > Framework & Tool' 카테고리의 다른 글
| gRPC (0) | 2021.07.09 |
|---|
기존 포스팅에서 종종 Actor를 언급을 했습니다.
Akka Framework에 대해 포스팅하려다가
Actor가 무엇인지, 왜 필요한지를 먼저 정리해봤습니다.
1. Background
CPU Clock 성능 진화의 한계 도달
(무어의 법칙은 무너진 지 오래)
CPU는 현대에와서는 질보다 양적 증가로 이어져 왔습니다.
양적 증가로 인해 여러개의 CPU를 잘 사용하여 하드웨어의 성능을
따라갈 수 있도록 소프트웨어에서 병렬 처리가 필요해졌습니다.
이를 보고 유명한 프로그래머이자 져널리스트인
허브 셔터(Hurb Shutter)가 아래와 같은 말로
동시성 프로그래밍 시대를 표현했습니다.
Free launch is over
- Hurb Shutter -
공짜 점심은 끝났다. (성능 날먹은 끝났다.)
소프트웨어적인 노력이 필요해졌다라는
뜻으로 생각하면 됩니다.
워낙 대표적인 표현이라 Go Scheduling 포스트에서도
서론에 잠깐 언급했었죠.
Go/Golang Scheduling
Go Memory에 이어 이번엔 Go Scheduler입니다 Go는 일반적인 프로그래밍 언어들과는 달리 goroutine이라는 형태를 사용합니다 우리는 goroutine으로 기존의 thread 방식보다 편리하게 concurrency를 구현합니다..
syntaxsugar.tistory.com
먼저 병행성과 병렬성에 대해 정리하고 시작하겠습니다.
1.1 병행성(Concurrency) VS 병렬성(Parallelism)
- 병행성(Concurrency)
- 코어가 한 개여도 어느 순간 동시에 동작하는 것처럼 보이지만
동시가 아니라 한 개의 코어가 빠르게 번갈아 수행하는 것임 - 소프트웨어 수준의 처리로 구현
- 코어의 수가 2배가되어도 2배만큼 빨라질 수 없음(암달의 법칙)
- 예) Thread, Actor 등
- 코어가 한 개여도 어느 순간 동시에 동작하는 것처럼 보이지만
- 병렬성(Parallelism)
- 실제로 동시에 작업이 처리됨
- 멀티코어에서만 가능하며 코어의 수만큼 빨라짐
- 하드웨어 + 소프트웨어(병렬 알고리즘) 처리로 구현
- 두 가지의 작업 형태가 존재
- 데이터 병렬성 : 하나의 작업(Task)의 전체 데이터를 서브 데이터로 나눠 처리
- 작업 병렬성 : 서로 다른 작업을 동시에 처리
- 두 가지의 메모리 접근 방식이 존재
- 공유 메모리(Shared Memory)
- 여러 프로세서가 메모리 공유
- 접근 속도 동일
- 분산 메모리(Distributed Memory)
- 다른 프로세서의 메모리에 접근해야 할 수 있기 때문에 접근 속도 다름
- 공유 메모리(Shared Memory)
- 오버헤드 존재
- Communication : 작업을 나누어 전달, 결과를 통합
- Load Balancing : 코어별로 동등하게 작업을 나눠야 함
- Synchronization : 크리티컬 섹션에 대한 접근 문제
- 예) OpenMP, CUDA 등
위와 같이 명확하게 구분할수 있지만
별 구분 없이 쓰이기도 합니다.
이 포스팅에선 병행성에 대해서만 다룹니다.
병렬성은 나중에 다루게될지 모르겠네요.
병행성으로도 멀티코어 활용이 가능하며
멀티쓰레드 등의 활용은 프로그래밍의 기본적인 내용이 되었습니다.
1.2 쓰레드(Thread)
동시성 프로그래밍에서 중요한 것은 성능과 안정적인 처리 두 가지입니다.
일반적으로 개발자들은 멀티쓰레드로 동시성 처리를
해왔지만 쓰레드는 오래된 기술이고 안정성 측면에서
잘 알려진 몇 가지 문제가 존재합니다.
복잡하고 어려우며 잠재적인 버그 발생의 원인
- 쓰레드 간 공유되는 데이터는 개발자가 관리해야 함
- 비결정성(Non-Deterministic) 때문에 버그가 발생하여도
재현하기도, 디버그 하기도 어려움- 운영체제가 쓰레드 실행을 관리
- 공유 데이터의 처리
- 같은 데이터에 동시 접근하는 것을 막기 위해(Data Race)
mutex lock 등의 처리가 필요 - dead lock, starvation, 누락된 처리 등까지 고민해야 함
- 같은 데이터에 동시 접근하는 것을 막기 위해(Data Race)
대표적으론 위와 같이 존재하며
애초에 쓰레드만의 문제라기보단 병렬 처리 자체가
비결정적이기 때문에 사람의 머리로 예측하기 어렵습니다.
여기에 공유 데이터와 크리티컬 섹션의 처리를 생각하면
성능 이슈까지 존재하게 됩니다.
쓰레드를 사용하는 대부분의 프로그램들은 버그로 가득 차 있다.
- Havoc Pannington-
이러한 문제들의 최선의 해결책으로 Actor 모델이 사용되고 있습니다.
2. Actor Model
Actor는 어떻게 비동기, 동시성 처리를 가능하게 할까요?
객체 지향에서 '모든 것은 객체(Object)다'라고 생각하는 것처럼
Actor 모델에서는 '모든 것은 액터(Actor)다'라는 철학이 있습니다.
객체를 사물에 비유하듯이
Actor라는 것도 추상적인 개념이기 때문에
사람이라고 비유하면 이해하기가 쉽습니다.
2.1 Concept
쓰레드라는 구조가 동작하는 것처럼
Actor라는 구조가 있습니다.
위 그림과 같이 Actor는 세 가지로 구성됩니다.
- Behavior : 행동
- State : 상태(변수)
- Mailbox : 수신함(큐)
쓰레드가 여러개로 동작하듯이
Actor도 여러개가 동작합니다.
init, ready, closed 등의 상태를 정의할 수 있고
매순간 정의된 상태 중 하나의 상태를 가집니다.
(상태를 변수로 갖고 있다고 생각하면 됩니다.)
Actor 간에는 메시지를 주고 받을 수 있습니다.
메시지는 여러 종류를 정의할 수 있습니다.
(메시지는 구조체 형식이라고 생각하면 됩니다.)
Main문에서 Actor를 지정해 메시지를 보내면
해당 Actor의 수신함에 메시지가 들어가고
수신한 Actor는 이벤트가 발생해
받은 순서대로 메시지를 확인합니다.
메시지를 수신한 Actor는 메시지 종류를 구분합니다.
구분하여 적절한 행동을 취하도록 정의합니다.
switch 문을 생각하면 쉽습니다.
switch 메시지 {
case A: 행동X 수행
case B: 행동Y 수행
case C: 행동Z 수행
default: 모르는 메시지에 대한 행동 수행
}
쓰레드가 run되면 수행할 행동을 정의하듯이
Actor가 메시지를 받으면 수행할 행동을
이러한 switch문 형식으로 정의한다고 이해하면 됩니다.
다시 정리해보겠습니다.
Actor는 Behavior(행동), State(상태), Mail Box(수신함)으로 구성됩니다.
- State는 메시지를 수신하였을 때, Actor 자신만 변경 가능
- Mail Box에 쌓인 메시지는 순서대로 처리함
- 수신한 메시지에 따라 Behavior를 결정하여 실행
Behavior는 다음과 같습니다.
- 자신의 State 변경
- Child Actor 생성 및 제거
- 다른 Actor에 메시지 전송
- + 그 외 Actor가 수행하길 원하는 모든 동작
Object와 Actor는 아래와 같은 측면에서 비교될 수 있습니다.
- Object는 Method를 호출하여 동기적으로 작업이 수행
- Actor는 Message를 보내어 비동기적으로 Behavior를 수행
동기?
- 기본적인 프로그램 방식
- 이전에 수행한 작업이 완료되어야 다음 작업 수행
- 이전 작업을 완료될 때까지 멈추므로 Blocking 방식이라고도 함
비동기?
- 쓰레드 등을 이용한 방식
- 작업을 동시에 처리
- 작업을 기다리지 않고 각자 주어진 일을 하므로 Non-Blocking 방식이라고도 함
공식적으로는 아래와 같이 설명되어 있습니다.
Actor는
- 다른 Actor에게 유한 개수의 메시지를 보낼 수 있다.
- 유한한 개수의 새로운 Actor를 만들 수 있다.
- 다른 Actor가 받을 메시지에 수반될 행동을 지정할 수 있다.
- 이러한 작업은 동시적으로 진행되고 정해진 순서는 없다.
칼 휴이트 (Carl Hewitt), 1973
위의 내용을 정리해봅시다.
- Actor는 독립적인 메모리 공간을 갖는다.
- Actor 간의 상호작용은 메시지를 통해 이루어진다.
라는 기본적인 개념을 가집니다.
이해를 위해 굳이 쓰레드와 비교하자면
1. 쓰레드처럼 각 Actor도 자신만의 메모리 공간을 가짐
2. 전역변수 등 공통으로 접근하는 값을 직접 변경해
다른 쓰레드에 영향을 미칠 수 있는 쓰레드와 달리
Actor는 다른 Actor로 메시지를 보내는 방법으로만
영향을 미칠 수 있음.
(Actor 외부에서 직접 변경하려하면 보통은 강제로 에러를 발생시킵니다.)
이 정도면 어렵지 않게 정리된 것 같습니다.
아직 감이 안잡혀도 아래의 그림이 이해는 되실겁니다.
메모리를 공유하지 않으니 공유 데이터의
처리를 고민할 필요가 없어지는 것이죠.
우리는 머리 아프게 이 이상으로
복잡한 케이스를 고민할 필요가 없습니다.
각 Actor만 잘 정의하면 아래와 같이
복잡한 형상이 되더라도 문제없이 동작합니다.
Actor가 수신한 메시지는 아래 그림과 같이 쌓이게 되고
처리 중인 메시지가 끝나면 다음 메시지를 꺼내 처리합니다.
메시지는 순서대로 처리됩니다.
Actor의 내부 동작은 쓰레드풀로 구현되어 있습니다.
하지만 Actor마다 하나의 쓰레드가 할당되는 개념이 아니라
주어진 쓰레드풀에서 필요한만큼 필요한 순간에
유동적으로 사용하는 방식입니다.
다시 말해 Actor는 쓰레드를 사용자가
직접 구현하지 않도록 하는것이 목표입니다.
사용자는 동시성 처리를 Actor에 맡기고
서비스 로직에만 집중하도록 하는것입니다.
Akka 등은 이러한 정신을 충실히 반영하고 있습니다.
즉, 쓰레드는 Actor 시스템이 내부적으로, 알아서, 훌륭하게 사용하고
튜닝 요소를 제공해 이를 간접적으로 조정할 수 있도록 하였습니다.
정확히 어떤 쓰레드가 어느순간에 어느 Actor로써 동작할것인지는
꽤나 복잡하며 Akka나 Erlang의 내부 구현을 알아야 합니다.
Akka의 경우 꽤나 자세히 설명이 되어 있기 때문에 궁금하면
Akka Dispatcher를 찾아보기 바랍니다.
(사용할 쓰레드풀의 크기는 직접 지정할수 있습니다.)
2.2 Fault Tolerance
Acto는 Fault Tolerance 한 특성까지 가집니다.
Actor는 "고장 나도록 내버려둔다('let it crash')"는 철학을 갖고 있습니다.
가능한 모든 문제 상황들을 예상하고 그것들을 다 다룰 수 있는 방법을 마련하는
방어적인 프로그래밍을 할 필요가 없도록 만들어줍니다.
(Cloud의 Container, Kubernetes의 Pod와 비슷한 그것이죠.)
고장 나면 어떻게 처리하길래 문제가 없을까요?
Actor는 Supervision이라는 개념을 사용합니다.
각 Actor는 사용자가 원하는 자유로운 방식으로 구현되어 사용될 수도 있지만
일반적으로 Supervision 한 패턴으로 구현이 됩니다.
Supervision이 뭘까요?
각 Actor는 Child Actor를 생성하고 메시지를 보낼 수 있습니다.
Child Actor를 생성한 Actor는 해당 Child의 Parent Actor가 됩니다.
Child Actor에서 문제가 발생하면 이를 Parent Actor에 통보하고,
Supervisor로써 적절한 전략으로 처리합니다.
여기서부터 상세한 사항은 시스템에 따라 전략이 다를 수 있습니다.
가장 널리 알려진 Akka Actor를 예로 설명하겠습니다.
Parent Actor는 Supervisor로써 Child Actor를 생성해 업무를 나누어주고,
Child Actor의 실패(예외 등)를 Handling 하는 역할을 수행합니다.
Child Actor가 실패를 감지했다면 자신의 하위 Actor들을 모두 Stop 하고,
Parent에게 실패를 알리는 메시지를 전달합니다.
Supervisor는 실패 메시지를 4가지 전략(Streategy)을 옵션으로 처리할 수 있습니다.
- Resume the subordinate, keeping its accumulated internal state
Child Actor 동작 재개 - Restart the subordinate, clearing out its accumulated internal state
Child Actor의 State를 초기화하여 재시작 - Stop the subordinate permanently
Child Actor 제거 - Escalate the failure, thereby failing itself
실패를 확장하여 Supervisor 자신도 실패 처리
이를 아래와 같이 예외 별로 처리할 수도 있습니다.
(Akka 예시입니다. 개인적으로 꽤 마음에 드는 처리입니다.)
import akka.actor.OneForOneStrategy
import akka.actor.SupervisorStrategy._
import scala.concurrent.duration._
override val supervisorStrategy =
OneForOneStrategy(maxNrOfRetries = 10, withinTimeRange = 1 minute) {
case _: ArithmeticException => Resume
case _: NullPointerException => Restart
case _: IllegalArgumentException => Stop
case _: Exception => Escalate
}
이러한 형상으로 Actor는 자가 회복하는 시스템을 가질 수 있습니다.
Supvisor가 crash 된 Actor를 안정된 상태로 되돌리기 위한 작업을 할 수 있기 때문이죠.
(가장 흔히 채택되는 전략은 Actor를 재시작하여 초기 상태로 만드는 것입니다.)
Actor의 핵심 정신은 Correctness입니다.
위에서 설명한 내용은 예시로써 기본적인 Actor의 처리이며
실제로는 안정적인 처리를 위해 더 상세한 내용들을 고려하고 있습니다.
제가 이 포스팅에서 일부만을 설명하는 것으로 오해를 유발하거나
정확한 내용을 파악하지 못하게 할 수 있다고 생각합니다.
실제로 사용하거나 더 자세한 사항을 알기 위해서는
해당 Actor의 문서나 코드를 참고하기 바랍니다 :)
2.3 Distribution
Actor의 주목할 만한 또 하나의 측면은 자신이 메시지를 보내는 대상이
로컬에 있는지 또는 다른 노드에 있는지 전혀 신경 쓸 필요가 없다는 점입니다.
Actor는 우편함과 상태를 갖고 메시지에 응답할 필요만 있는데 그 Actor가
어떤 머신에서 도는 게 문제가 될까요?
보낼 메시지만 제대로 도착한다면 문제가 없습니다.
즉, 여러 대의 컴퓨터가 상호작용하고 한 대가 죽은(fail) 경우 다른 하나가
그의 회복을 돕는 시스템을 구성하는 것도 문제가 없습니다.
Akka를 예로 간단히 살펴보겠습니다.
Akka의 각 Actor는 유니크한 구분을 위해 path 방식의 Identity를 가집니다.
애초에 REST API처럼 URL 기반의 Identity를 갖기 때문에 이해하기 편합니다.
Remote의 Actor에 메시지를 보내어 상호작용하는데 문제가 없습니다.
이러한 구조 때문에 Clustering, Sharding 등의 처리도 용이하며 Akka에서 지원하고 있습니다.
3. Drawback
Actor의 단점은 어떨까요?
- 구현이 각 Actor 별로 퍼져있어 코드가 읽기 어려워질 수 있다.
- 공유하는 리소스 없이 모든 상호작용이 메시지로 동작하기 때문에 통신 비용에 의한 성능 문제가 발생할 수 있다.
개인적인 의견으로는 사실 Actor 자체의 커다란 단점을 찾기 애매합니다.
전문가들과 학문적으로도 많이 고려된 모델이기 때문에 다들 단점을
언급하기에 조심스럽다는 느낌까지 듭니다.
안정성도 안정성이지만 기본적으로 동시성 처리의
주목적은 성능이기 때문에 가장 큰 이슈는 아무래도 성능이겠죠.
성능예측이 간단하지 않은 이유 중 하나는 CPU와 쓰레드의 상관관계 때문입니다.
쓰레드가 무조건 많다고 성능이 좋아지지 않으며 특정 쓰레드 개수를 초과하는 경우
성능이 하락합니다.(context-switcing 등의 overhead)
Actor도 내부적으로 쓰레드를 사용하여 구현되어 있습니다.(Actor is not magic.)
하나의 Actor가 동작할 때 하나의 쓰레드가 할당되어 동작합니다.
(단, Actor가 동작하지 않는 경우, 휴식 상태로 들어가며 쓰레드가 할당되지 않습니다.)
쓰레드 최적화가 이루어지지만 통신 비용이 클것이라 생각이 들어서
특정 상황을 제외하고는 성능이 조금 떨어질 수밖에 없다고 생각이 드는데요.
정리하면서 저도 궁금해져 찾아보는데 생각한 내용을 찾기 힘드네요.
가장 괜찮은 문서는 Denis Kroeb의 Benchmarking Akka입니다.
현재 아래 링크로 받아 볼 수 있습니다.
https://scripties.uba.uva.nl/download?fid=679533
논문을 대강 봐서는 초기화 비용을 제외하고서 비교했을 때
쓰레드의 개수가 많아지지 않는 경우 대부분의 상황에서
Actor가 더 잘 나오는 것으로 보입니다.
크리티컬 섹션이 많은 구간에선 Actor가 더 잘 나올 것이라 생각했는데
단순 Couting으로 계산한 것인데도 이러한 결과가 나왔습니다.
아마 Actor 구현 자체로 내부에 쓰레드풀을 포함하고 있고
쓰레드는 쓰레드 생성비용 까지 포함되어 측정되었기 때문이라고 생각이 드는데
해당 실험이 Actor에 의해 동작하는 실제 쓰레드 개수와 쓰레드풀 방식과 비교하지 않은 것이 아쉽네요.
위에서 언급했듯이 Actor는 하나 당 하나의 쓰레드가 무조건 할당되는 방식이 아니기 때문에
생성 비용에서 훨씬 더 가벼울 수밖에 없습니다.
쓰레드는 보통 쓰레드풀을 사용하기 때문에 위의 결과가
정확히 성능 비교를 하기엔 어렵다고 생각이 들지만
최적의 쓰레드양을 모르는 상태에서 쓰레드 생성 비용을
감수하는 것보다는 Actor를 사용하는 것이 성능 측면에서도 유리하다고 볼 수 있겠습니다.
자세한 부분은 저도 논문을 정독해봐야겠습니다.
Actor도 성능을 튜닝할 수 있는 부분이 많기도 해서
시간 나면 정독하면서 직접 실험도 해볼까도 생각 중입니다.
Ruby를 만든 Yukihiro Matsumoto는 인터뷰 중에 이런 말을 했다고 합니다.
Bruce : 그때(루비를 만들었을 당시)로 돌아간다면, 어떤 기능에 변화를 주고 싶으세요?
Matz : 쓰레드를 없애고 Actor나 또는 진보된 형태의 동시성 기능을 추가했을 거예요.
유독 동시성 처리 관련해서 유명한 말이 많네요ㅎㅎ
그만큼 동시성 처리가 어렵고 많은 기술자들이 고민하는 분야이기도 하고
Actor가 많이 고려되는 모델입니다.
저도 그랬지만 Actor는 사실 처음 접하면 익숙하지 않은 방식인 건 사실입니다.
상세하게 익히는데 시간이 걸릴 수도 있지만 Correctness만큼은 확실하게 보장하는 모델입니다.
Erlang과 Scala의 Akka에서 Actor 모델을 채택하고 있으며
특히 Akka는 전문가들에 의해 굉장히 잘 설계된 Actor라 평 받고 있습니다.
(Akka를 사용하면 코드가 지저분하다는 지적이 있긴 하지만...)
특유의 안정적인 동작 덕분에 Go에서도 종종 사용되고 있습니다.
GitHub - asynkron/protoactor-go: Proto Actor - Ultra fast distributed actors for Go, C# and Java/Kotlin
Proto Actor - Ultra fast distributed actors for Go, C# and Java/Kotlin - GitHub - asynkron/protoactor-go: Proto Actor - Ultra fast distributed actors for Go, C# and Java/Kotlin
github.com
다음 Actor 포스팅에서는 Actor를 사용해서 Best Example을
만들어 볼까 하는데 Go의 Actor를 사용할지 고민이 되네요.
요즘 Go에 빠져서 Go의 동시성에
Channel, Goroutine, Actor를 비교하고 싶은 욕구가 듭니다.
'Programming > Framework & Tool' 카테고리의 다른 글
| gRPC (0) | 2021.07.09 |
|---|